


The long and the short of IT
AI RAG: "Look at me the same way you look at pizza"


Google’s GenAI LLM (Gemini) advises that glue is a pizza topping. Gourmets sigh. We are reconciled to the hallucinations and the lack of transparency in LLMs. For example GPT-4 pre-training uses both public data and "data licensed from third-party providers" to predict the next token. But the failure of LLM developers to disclose inner model workings, and those recent LLM pratfails makes it unsettling for governance-centric CIOs to adopt the technology. It mattered less in the early adoption ‘tyre-kicking’ PoC stage, but for inference this gets unpalatable. We are RAG fanboys seeing in RAG the opportunity to update LLMs, reduce hallucinations, add industry relevancy and context, help with transparency. To be sure, RAG does not help on ‘cause and effect’ understanding but RAG is at the intersection of GenAI and practical business applications. Generally we are encouraged: (i) our RAG selection outperforms the UK tech sector (+12.4% YTD vs Sector +11.4%) and still trades on a sub-sector rating (below) and, (ii) on the menu in the latest Foundation Model Transparency Index is a “significant improvement in LLM transparency”. The authors admit that transparency “has been declining for several years, and this trend is unlikely to reverse in the near term”. Transparency disclosure can be gamed but for us any incremental disclosure helps regulation (White House, G7, Walbrook AI Accord etc), user organisations, transparency advocates, the wider stakeholder and investment community. This ‘pizza’ research explores our ‘RAG to Riches’ investment thesis and our cohort views on Capita, Experian, LSE, MONY, Pearson, Relx, S4C, Trustpilot.
The Foundation Model Transparency Index - latest findings
The Foundation Model Transparency Index was launched in October 2023 to measure the transparency of leading foundation model developers. The first Index (v1.0, October 2023) assessed 10 major foundation model developers on 100 transparency indicators (e.g. does the developer disclose the wages it pays for data labour?). As developers publicly disclosed very limited information the average score was 37 out of 100. The second edition (V1.1, May 2024) scored 14 developers against the same 100 indicators with added reports from the developers that potentially included non-public information. The 14 LLMs in V1.1 are Adept, AI21 Labs, Aleph Alpha, Amazon, Anthropic, BigCode/Hugging Face/ServiceNow, Google, IBM, Meta, Microsoft, Mistral, OpenAI, Stability AI and Writer. The V1.1 score, 58, is a 21-point improvement over v1.0 (see below). The uptick is due to:
Developers disclosing information during the v1.1 process: on average, developers disclosed information related to 16.6 indicators that was not previously public.
Sustained and systemic (i.e. across most or all developers) opacity such as on copyright status, data access, data labour, and downstream impact.
The interpretation
The findings provide significant reasons for optimism about the prospects for improved transparency. Developers shared a significant amount of new information about how they build, evaluate, and deploy their models.
Some of the areas that were least transparent in v1.0 show significant improvement in v1.1, like compute, methods, risks, and usage policy.
Several companies have become much more transparent, with some releasing model cards or other documentation for their flagship foundation models for the first time. By engaging directly with foundation model developers, the report shows that many firms are willing to disclose more information about.
The overall state of transparency remains poor.
Developers are opaque about the data, labour, and compute, they often do not release reproducible evaluations of risks or mitigations, and they do not share information about the impact their models are having on users or market sectors.
Transparency has been declining for several years, and this trend is unlikely to reverse in the near term.
The problem that RAG Addresses
Sorry pizza fans, but if you are using LLMs for fact-based answers, you must fact-check. Today’s LLM technology does not help developers to extract rogue learnings from an already-trained model. In addition there is less transparency around the training data. To be sure, you can have keywords and phrases on blacklists, you can back-check model responses for instances of specific text bias. Beyond these workarounds companies are developing solutions based human review and/or on Retrieval-Augmented Generation, RAG (RAG defined).
RAG thinking dates to a December 2020 whitepaper by Meta. Meta came up with a framework called retrieval-augmented generation designed to give LLMs access to information beyond their training data. RAG would allow LLMs to build on a specialised body of knowledge to answer questions in a more accurate way. Thereby RAG would enhance the accuracy and reliability of GenAI LLMs with up-to-date facts and answers the need for trusted data in factual, data-centric decision-making processes. RAG has additional benefits. The concern that while LLMs generate response based on their training data, which is mostly from the Internet, to get answers from non-public data (such as in a corporate setting) the LLM must be upgraded. This is what RAG does and using them means that there is no need to re-train an LLM (expensive – and requiring more data), and hallucinations are reduced as answers are source from the proprietary data instead of the LLM directly. By grounding an LLM on a set of external, verifiable facts, a RAG-based model has fewer opportunities to leak sensitive data.
RAG has two phases: retrieval and content generation, as follows:
Retrieval: Algorithms search for and retrieve snippets of information relevant to the user’s prompt. The facts could come from indexed documents on the internet or a from a narrower knowledge pool inside a corporate. The answer is then passed to the language model.
Content generation: LLM draws from the prompt and training data to synthesise an answer which could be (say) passed to a chatbot with links to its sources.
RAG fill a large gap and makes LLMs more profitable. We do not hear much about RAG because we are at the test stage for GenAI adoption and the volume bit (inference) comes later. Inference is where getting the wrong answer equals problems. Inference is the process of drawing conclusions about the state of a data set based on the observed data. Without inference, a machine would not have the ability to learn. It is how you run live data through a trained AI model to make a prediction, or solve a task, achieved through an “inference engine” that applies logical rules to the knowledge base that then evaluates and analyses new information. We see two phases:
Training where intelligence is developed by recording, storing, and labeling information. If you are training a machine to identify boats, the machine-learning algorithm is fed with images of different boats the machine can later refer to.
Inference where the machine uses the intelligence gathered and stored in phase one to understand new data. In this phase, the machine can use inference to identify and categorise new images as “cars" despite having never seen them before. Inference learning can be used to augment human decision making. For maximum reliability, energy efficiency, privacy and to minimize latency.
Some will ask how RAG contrasts with fine-tuning a pretrained model, as follows:
Fine-tuning adjusts a model’s weights, to create a more custom model and is an option for users that rely on codebases written in a specialized language. This is especially the case if the language is not in the model’s original training data.
RAG does not require weight adjustment. Instead, it retrieves and gathers information from a variety of data sources to augment a prompt, which results in an AI model generating a more contextually relevant response for the end user.
Sidebar: Where vector database technology fits into the equation
The model initially conducts a semantic search within a database often a vector space organised as a collection of numerical representations of various data points, including text, images and audio. Vector databases are best suited as they are good for storing and managing unstructured data and by converting them into high-dimensional vector embeddings they capture the semantic relationships between data points. The primary strength of vector databases lies in their ability to handle large volumes of data and perform semantic searches at scale.The most popular vector database is from KX (from FD Technologies plc), others include Pinecone, Chroma and Weaviate. When a RAG system queries a vector database, it quickly identifies mathematically close vectors, which imply similar meanings, rather than relying solely on keyword matching.The retrieval mechanism is designed to understand the semantic relationships between the query and the database contents, ensuring that the data selected is contextually aligned with the query's intent. To perform similarity search and retrieval you select a query vector that represents the desired information. The query vector can be based on the same type of data as the stored vectors or from different types. Then, you employ a similarity measure that calculates how close or distant two vectors are in the vector space (model weights) which rank a list of vectors that have the highest similarity scores with the query vector. You can then access the corresponding raw data associated with each vector from the original source.
LSE AI RAG cohort
Capita
Capita has been battered over the past years. Capita offers consulting, transformation and professional delivery services, drawing on its practical experience, and provide digitally enabled services and solutions. Capita deserves inclusion in our RAG list because of it deep domain expertise in the UK Public Sector where it is a Strategic Supplier. Its vast experience in outsourcing gives it domain knowledge of Public sector processes. Capita has been in the doldrums for years, but the appointment of Adolfo Hernandez puts a technologist and one very familiar with AI technologies as CEO. Capita has two divisions: Capita Public Service and Capita Experience in the UK, Europe, India and South Africa.
Capita Public Service division provides applied digital transformation and Business Process as a Service to improve the productivity and citizen experience. The division is focused on education, learning; local public services; health and welfare; defense, security and fire; justice, policing; transport, central government.
Capita Experience Division is engaged in “designing, transforming and delivering experiences for the life moments”. Its serves various industry verticals: telecoms, media & technology; retail & consumer products; energy and utilities; government, transport and financial services.
At final (6/3) results CEO Mr Hernandez (i) reminded that he has spent half of his career in software, half in services “always in the boundary of seeing how you could apply software to modernise services, or how you can build services wrappers around software to augment value”. (ii) Flagged a June CMD which will outline the growth strategy. Knowing Mr Hernandez we expect GenAI to improve internal processes and externally with customers.
Experian
A global information services company, Experian spans B2B and Consumer Services. The company is included in our RAG cohort because it builds and manages large comprehensive databases, where it collects, sorts, aggregates and transforms data from tens of thousands of sources, to provide a range of data-driven services. Experian has databases and third-party information, including client’s own data, which it combines to create and develop analytics, predictive tools, software and platforms. Its services help its clients improve the consistency and quality of their business decisions, in areas including credit risk, fraud prevention, identity management, customer service and engagement, account processing, and account management.
Since our last update on 22 May Experian debuted a suite of enhancements to its cloud-based Experian Ascend Technology Platform. This was improved experience and useability by bringing analytics, credit decisioning and fraud into a single pane to simplify deploying analytical models. It also offers streamlined access to many of Experian's solutions and tools through a single sign-on and managed via a dashboard. The platform is used by 1,500+ clients, processing 14m credit reports daily, and “billions of credit and fraud transactions” a year. In North America, 8,000+ registered users access over 12 petabytes of data weekly for analytical purposes. Experian says that by using GenAI it has made it “easy for clients to move between applications, automate processes, modernise operations and drive efficiency”.
London Stock Exchange
We encourage investors to see LSEG as a global data provider and financial markets infrastructure. The company deserves its RAG inclusion because of the wealth of data points on trading patterns. At final results (29/2), CEO David Schwimmer commented that the first new products from its Microsoft partnership would debut by Summer. By the Q1 Trading Update (25/4) Mr Schwimmer added that a number of those products are expected to be in external pilot or general release “this half”, and that the LSE is “picking up the pace of migrating our datasets onto the Microsoft platform, which will transform access to our data for customers”. Our view is unchanged: With Microsoft as a partner and shareholder, LSE has a seat at the table at the heart of OpenAI development thinking and will thereby be aware of its RAG opportunity. The LSEG has three divisions, as follows:
Data & Analytics (66% of FY23 revenue) provides information and data products, including indexes, benchmarks, real-time pricing data and trade reporting and reconciliation services. Data & Analytics division includes the core Refinitiv business and the FTSE Russell businesses.
Capital Markets (19% of FY23 revenue) provides venues/platforms for access to capital through issuance and secondary market trading for equities, fixed income, and foreign exchange (FX).
Post Trade (15% of FY23 revenue) provides clearing, risk management, capital optimisation, and regulatory reporting.
Moneysupermarket.com/MONY
Moneysupermarket.com has a wealth of information about consumer saving and spending patterns, its data is a treasure chest. The company operates price comparisons for money, insurance and home services and its segments include Insurance, Money, Home Services, Travel and Cashback.
Insurance: Services include the customer completing transactions for an insurance policy on the provider’s Website, website or a telephone call.
Money: Customers completing transactions for money products, such as credit cards, loans and mortgages on the provider's Website.
Home Services: Customers completing transactions for home services products, such as energy and broadband on the provider's Website.
Travel: Customers completing transactions for travel products on the provider's Website or its Website.
Cashback: Customers completing transactions for retail, telecommunications, services and travel products with a cashback incentive on the merchant's Website.
This is a technology-enabled business with a tech stack based on ‘Decision Tech’ its UK price comparison platform which creates digital experiences that connect users with the right products and services. We see the application of RAG there and in the SuperSaveClub. The SuperSaveClub is a 300k member loyalty and rewards programme which gives customers “more ways to save with us”. As the Q1 Trading update (16/4) CEO Peter Duffy commented that by helping UK households “save on their bills, we create sustainable and profitable growth for the Group.”
Note: On 22 May, Moneysupermarket.com Group plc became MONY Group plc. This reflects the evolution beyond the original price comparison website. The corporate website address is changed to www.monygroup.com.
Pearson
Pearson is a learning company with its principal operations in the education, assessment and certifications markets. Inclusion in our RAG cohort is due to the deep domain expertise in learning, and ‘all of life’ learning and thereby the company’s ability (admittedly unproven) to have an actual LTV. The operating divisions are:
Assessment & Qualifications: Pearson VUE, US Student Assessment, Clinical Assessment, UK GCSE and A Levels and International academic qualifications and associated courseware including the English-speaking Canadian and Australian K-12 businesses.
Virtual Learning: Virtual schools and online program management.
English Language Learning: Pearson Test of English, Institutional Courseware and English Online Solutions.
Workforce Skills: BTEC, GED, TalentLens, Faethm, Credly, Pearson College and Apprenticeships.
We were encouraged by the Q1 Trading Update (26 April) where Pearson admitted that it was continuing to infuse AI into its products and was “on-track to include AI features in more than 40 Higher Education titles for the Fall semester”.
Relx
Relx, once Reed Elsevier, under CEO Erik Engstrom pivoted to information-based analytics and decision tools, and hence its inclusion within our RAG listing. Final results (15/2) were pleasing, 2023A revenue £9.2bn, £8.6bn Y/Y with tech and data analysis being 83% of total and grew 7% Y/Y, with operating profit £2.7bn, £2.3bn Y/Y. The company employs c11,000 technologists (total FTEs 35k) and spends c£1.3bn/ year on IT. Across the portfolio, Relx has begun to debut AI products. Our impression is that it is taking a softly-softly approach, with few datapoints being disclosed at the results conference. However, the Relx structure suggests plenty of opportunities:
Risk (34% of FY23 revenue): Information-based analytics and decision tools that combine public and industry-specific content with advanced technology and algorithms to assist them in evaluating and predicting risk and enhancing operational efficiency.
STM (33% of FY23 revenue): Information and analytics that help institutions and professionals progress science, advance healthcare and improve performance.
Legal (20%): Provides legal, regulatory and business information and analytics that help customers increase their productivity, improve decision making and outcomes.
Exhibitions (12%): Connect digitally and face-to-face, learn about markets, source products and complete transactions.
The AGM Trading update (25/4) was positive (reiterated FY guidance) and we note that Relx has made progress in the Legal division with the debut of Lexis+AI, a new platform leveraging value-enhancing GenAI functionality which “continues to go well”.
S4Capital
S4Capital, founded by the incomparable (and indefatigable) Sir Martin Sorrell, is a global (geographical markets includes the Americas, EMEA and Asia Pacific) digital advertising, marketing, and technology services company. The Company’s inclusion on the RAG listing is due to the deep knowledge of the Adtech and Martech worlds along with the digitisation of Advertising, where we see much opportunity for process re-engineering. S4C is a digital native across its three operating segments:
Content (62% of Q1 net revenue): Offers creative content, campaigns, and assets at a global scale for paid, social and earned media from digital platforms and applications to brand activations.
Data & Digital Media (25%): Provides full-service campaign management analytics, creative production and advertisement serving, platform and systems integration and transition and training and education.
Technology Services (13%): Engaged in the digital transformation services in delivering digital product design, engineering services and delivery services.
While the Q1 trading update (10/5) was mixed (“macro-economic uncertainty and client caution, particularly amongst technology clients”), we took encouragement from: (i) New business activity continues at significant levels, and (ii) the strong AI positioning has led to winning “multiple exploratory assignments as clients experiment and explore applications and develop use cases. These are currently focussed on visualisation and copywriting, personalisation at scale and general client and agency efficiency.”
Trustpilot
A digital platform developing and hosting an online review platform that helps consumers make purchasing decisions and businesses showcase and improve their service. It hosts reviews to help consumers shop. We are big fans of the Company's platform which creates a place where businesses and consumers can gain actionable insights and collaborate. It is skill, and the resultant domain expertise, that warrants its inclusion on our RAG cohort.
Through its platform, consumers can share feedback, at any time, about any business with a Website and review feedback left by other consumers. The platform also gives consumers the opportunity to recommend businesses, products, services, and locations based on their experiences. Its consumers can search for reviews on any business by category and any business with a Website, whether operating online or offline, can receive a review.
The data
Foundation Model Transparency Index Scores by Domain, May 2024

Source: Foundation Model Transparency Index
Foundation Model Transparency Index scores, October 2023 & May 2024

Source:Foundation Model Transparency Index
AI RAG Constituents, Valuation heatmap & TSR: RAGs are cheap & have momentum
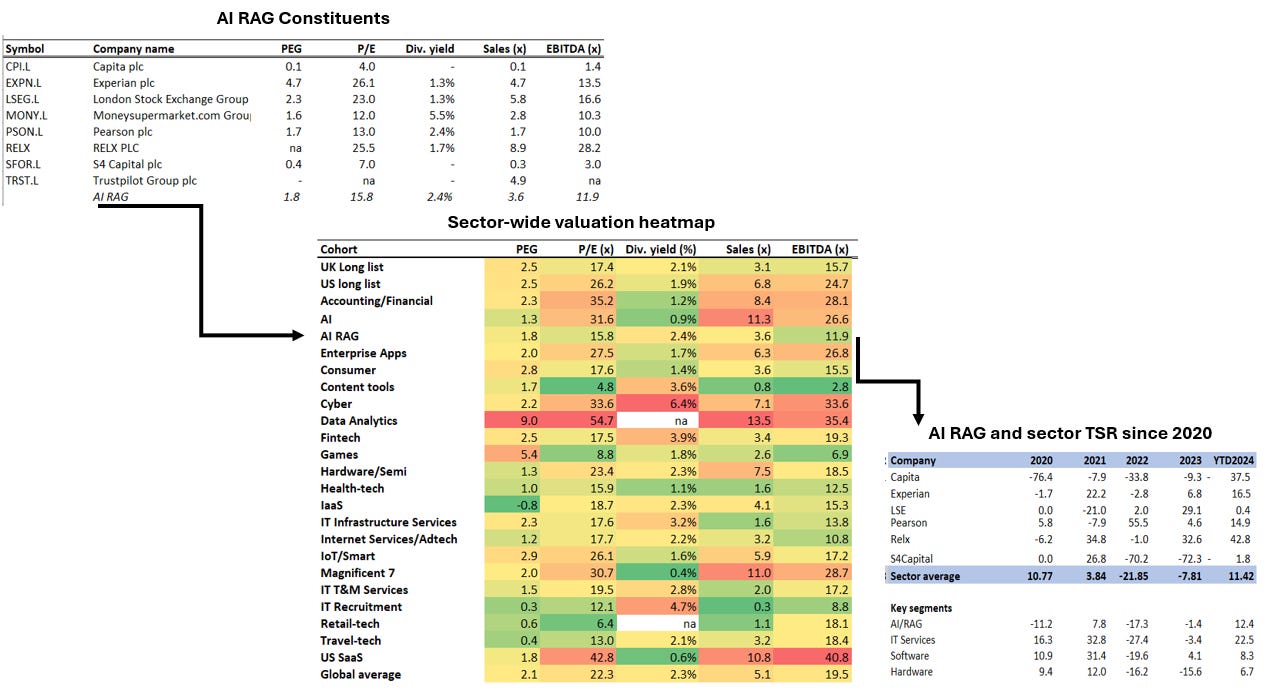
Source: Company data, Yahoo Finance, Analyst (George O’Connor)
How KX fits into the RAG equation

Source: Company data, Analyst (George O’Connor)
End notes & Disclaimer: Please read
All information used in the publication of this report has been compiled from publicly available sources that are believed to be reliable, however we do not guarantee the accuracy or completeness of this report and have not sought for this information to be independently verified. This is not investment advice. Opinions contained in this report represent those of the author at the time of publication. Forward-looking information or statements in this report contain information that is based on assumptions, forecasts of future results, estimates of amounts not yet determinable, and therefore involve known and unknown risks, uncertainties and other factors which may cause the actual results, performance or achievements of their subject matter to be materially different from current expectations. The author is not liable for any direct, indirect or consequential losses, loss of profits, damages, costs or expenses incurred or suffered by you arising out or in connection with the access to, use of or reliance on any information contained herein. The information should not be construed in any manner whatsoever as, personalized advice nor construed by any subscriber or prospective subscriber as a solicitation to effect, or attempt to effect, any transaction in a security. Any logo used in this report is the property of the company to which it relates, is used here strictly for informational and identification purposes only and is not used to imply any ownership or license rights between any such company and Technology Investment Services Ltd. Email addresses and any other personally identifiable information collected in the provision of the newsletter are only used to provide and improve the newsletter.
Need more
Let’s chat at Progressive Equity Research here where I am delighted to be a contributing analyst and my website here.
The ask
My name is George O’Connor. I am a tech investment and IT industry analyst. I explore shareholder value, its drivers, the best exponents, the duffers. The target readers are investors, companies, advisors, stakeholders and YOU. If you like this please subscribe and pass it on to colleagues and friends. That said, if you hate it - do the same. Thanks for dropping by dear investor.